

Prismatic is an integration platform used by B2B software companies to build reusable integrations and deploy customer-specific instances that handle each customer's unique configuration and credentials.
When we set out to create Prismatic, it was clear that we needed an API for our web app and CLI to use. Additionally, we wanted our developer users to be able to hit our API programmatically so they could manage customers and integrations as they saw fit. This presented a problem: different developers would naturally have different needs and use cases, and it didn't make sense to craft a series of custom RESTful endpoints for each individual's needs. GraphQL was growing in popularity (for good reason!) and was an appropriate choice for us given our needs.
Today I'd like to talk through our thought process as we designed our API, and why we decided GraphQL was the right choice for us.
What is GraphQL?
First, let's talk about what GraphQL is. If you're familiar with SQL databases, GraphQL will feel familiar. It's a query language, but instead of hitting a database you're hitting an API endpoint. For example, in a SQL-backed application your query for information about integrations might read something like this:
1
In GraphQL, you can make a similar query to an API endpoint:
123456789
Data-modifying SQL queries like DELETE, UPDATE have similar corresponding syntax in GraphQL. In GraphQL you issue "mutations", so you can do something like this to delete an integration:
1234567891011
Why did we choose GraphQL?
So, why did we choose GraphQL for our API? Simply put, it gave us more flexibility and let us work faster than if we had developed a standard RESTful API. Specifically, here are some of the advantages that made us choose GraphQL over REST:
1. Get exactly what you query for in a single request
With GraphQL, you as the client developer can query for whatever you want, and get back exactly what you requested. You can even request information about multiple resources with a single request and get as much or little information about each resource as you need.
To illustrate that, let's contrast how you would use GraphQL and REST with an example. Suppose we want to list the names of all of our integrations, along with the names of the customers we've deployed each integration to. If we had a RESTful API, I would expect there to be three endpoints that would help us gather that information:
[GET] /integrations– Returns a list of integrations, including each integration's name, ID, date of last publication, and who last published it.[GET] /integrations/<integration-id>/instances– Returns a list of instances of a specific integration, including the instance's ID, name, and the ID of the customer it was deployed to.[GET] /customers/<customer-id>– Returns information about a specific customer, including customer name, creation date, and IDs of the customer's users.
We could request information about our integrations from /integrations. Then, for each integration we could request a list of deployed instances from /integrations/<integration-id>/instances. Finally, for each instance we could request information about the customer the instance is deployed to from /customers/<customer-id>.

We could do all that... but there are some major problems:
- We over-fetched information. For our use case, we don't care about when the integration was last published or who published it. We don't need to know the names of the instances, and we don't need to know metadata about our customers (like user information or customer creation date). All we really care about are the names of the integrations, and the names of the customers they've been deployed to.
- We under-fetched information. What if
/integrations/<integration-id>/instancesyielded customer names instead of IDs? That may cause over-fetching elsewhere, but it would save us some round-trips to the API to get customer names. - We made multiple round trips. Suppose we have 50 integrations and each of those are deployed to an average of 20 customers. We would have made 1 call to
/integrations, 50 calls to/integrations/<integration-id>/instances, and(50 integrations) x (20 instances) = 1000calls to/customers/<customer-id>. 1051 API calls later, we'd have the information that we needed (plus a ton of extraneous information). Gross.

This over- and under-fetching of information, combined with what's commonly called the N+1 Problem of API development and which resulted in >1000 API calls, makes using this hypothetical RESTful API really unpalatable. Now, we could have created an all-new RESTful endpoint called /gimme-just-integrations-and-customer-names or something, but creating unique RESTful endpoints for each developer user gets unmaintainable pretty quickly.
Instead, let's look at the same problem with GraphQL. If we want just the names of integrations the names of the customers they're deployed to, we could issue a single query to the Prismatic API:
1234567891011121314
The GraphQL-base API will return a JSON structure with exactly the data we want in a single request:
123456789101112131415161718
That's much simpler, and definitely faster than issuing 1051 distinct API requests! Our backend server also appreciates handling a single request rather than 1051. Over- and under-fetching and multiple round-trips aren't just client issues, but affect server load, as well.
2. GraphQL is self-documenting
Some companies with complex APIs have entire teams dedicated to maintaining Swagger docs, turning API specs into readable documentation, etc. With GraphQL, you define how resources are interconnected (in Prismatic's case, an integration has multiple instances, an instance has a single customer, etc.), and schema about your API is automatically generated. Or, you can even go the other way – define some schema and your backend will auto-generate some stub entries and models!
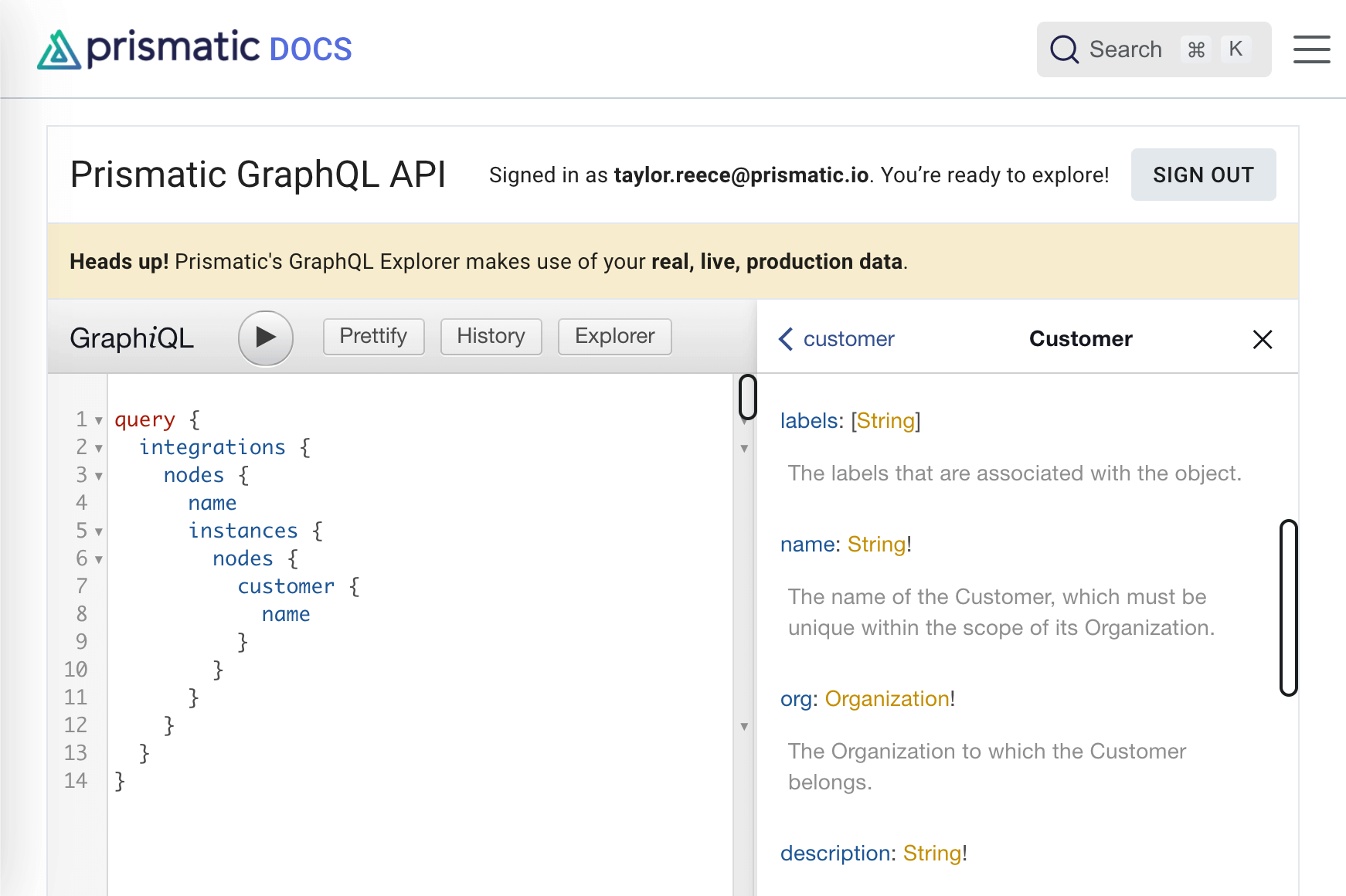
When you open up a GraphQL API client, the client queries the API for schema, so you can click through documentation and view resource relationships and properties as you build your GraphQL queries:
We use the auto-generated schema and pass it through a template engine to generate our API docs. As our API evolves and new features are added, new documentation is automatically generated without the need of human intervention! Our docs stay in sync automatically with our API.
3. Schema is strongly typed
Along with being useful for automatically generating docs, the schema that is generated is strongly typed, so you know exactly what kind of response to expect from your query. Not only does schema tell you if you should expect scalar types like String or Float, but it can tell you the structure of objects and their relationships. For example, a customer can have a list of labels of type String, and can reference the org of type Organization to which it belongs. Many GraphQL client libraries let you import schema, so responses from our API can be cast to strongly typed objects in your favorite programming language, and you can have fancy things like tab-complete, etc., all based on types declared in the API's schema.
Internally we use the GraphQL API schema to automatically generate TypeScript structures. That way, our node-based CLI tool and React web app have typing built in, and TypeScript can catch type mismatch errors between our API and application for us.
4. Keep devs moving quickly
As we built (and continue to add to) our web app and CLI tool, we're querying for different sets of data from our API. On some pages in our web app, we need a list customers and the instances that are deployed to them. For other pages, we only need IDs of instances, and don't render the name or any other data about them. Customizing RESTful endpoints for each of those pages would be silly, and our front-end developers would be left twiddling their thumbs as they waited for back-end developers to complete their work. Instead, front-end developers have the ability to craft their own GraphQL queries how they see fit, and can work independently from back-end developers. Our frontend developers can dramatically change the data displayed on a page and can make those changes without creating feature requests for corresponding backend changes.
5. Customer developers aren't locked into a specific language or tool
We encourage our developer users to use the Prismatic CLI tool, but they're by no means required to do so. You can manage deployment of integrations using your favorite language – most modern languages have one or more GraphQL clients. If you're a Linux or MacOS fan, you can even interact with the Prismatic API with curl from your terminal:
123456789
You'll hit the exact same API that the Prismatic web app and CLI tool do, so you can do anything with the API that you can do with either the web app or CLI tool.
How to hit the Prismatic API
Now that we've covered why we chose GraphQL, let's take a quick look at how to hit Prismatic's API. The easiest way to play with GraphQL queries is through our GraphiQL (pronounced "graphical") explorer tool in our docs. If you're signed in to the web app, you will automatically be signed in to this explorer tool.
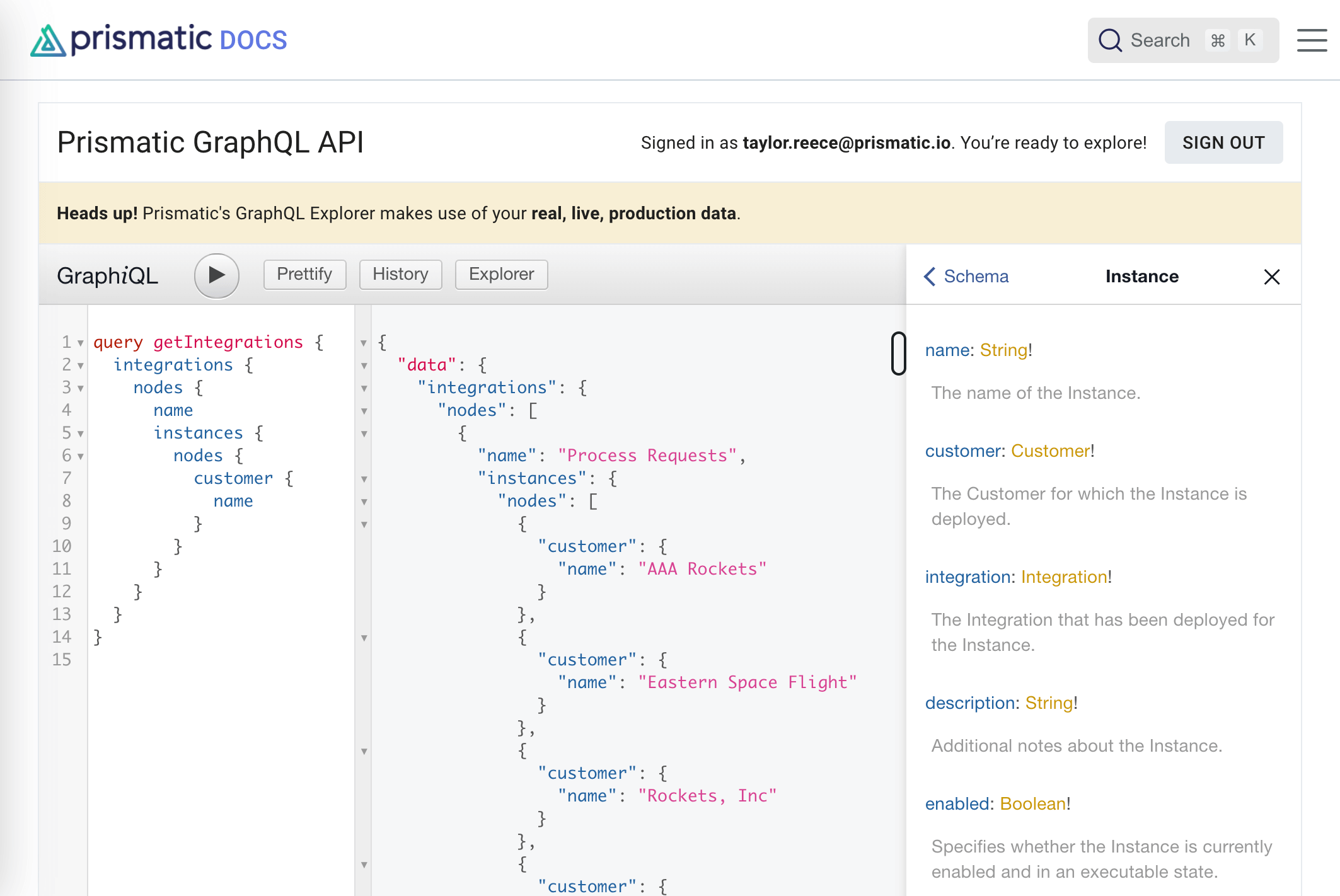
The explorer tool is handy for helping you craft your GraphQL queries and mutations, since documentation appears alongside the query as you write it. Once you're comfortable with our API, you can turn to GraphQL client libraries for your favorite programming language to query our API programmatically. For information on how to get an API token, and some examples for querying our API with curl, python, or JavaScript, check out our docs.


