Processing Data in Parallel
When you have a large set of records to process, you may want to process data in parallel to accelerate computation. This tutorial demonstrates how to process data in parallel by splitting the data into manageable chunks, and simultaneously processing each chunk.
For this example, you'll fetch a "large" dataset from the internet - here you'll pull down 500 "comment" records from the JSONPlaceholder API: https://jsonplaceholder.typicode.com/comments
Split the data into manageable chunks
Once you've fetched the data, you can use the Collection Tools component's Chunks action to split the data into manageable chunks. Here, you split the 500 records into 10 groups of 50 records each.
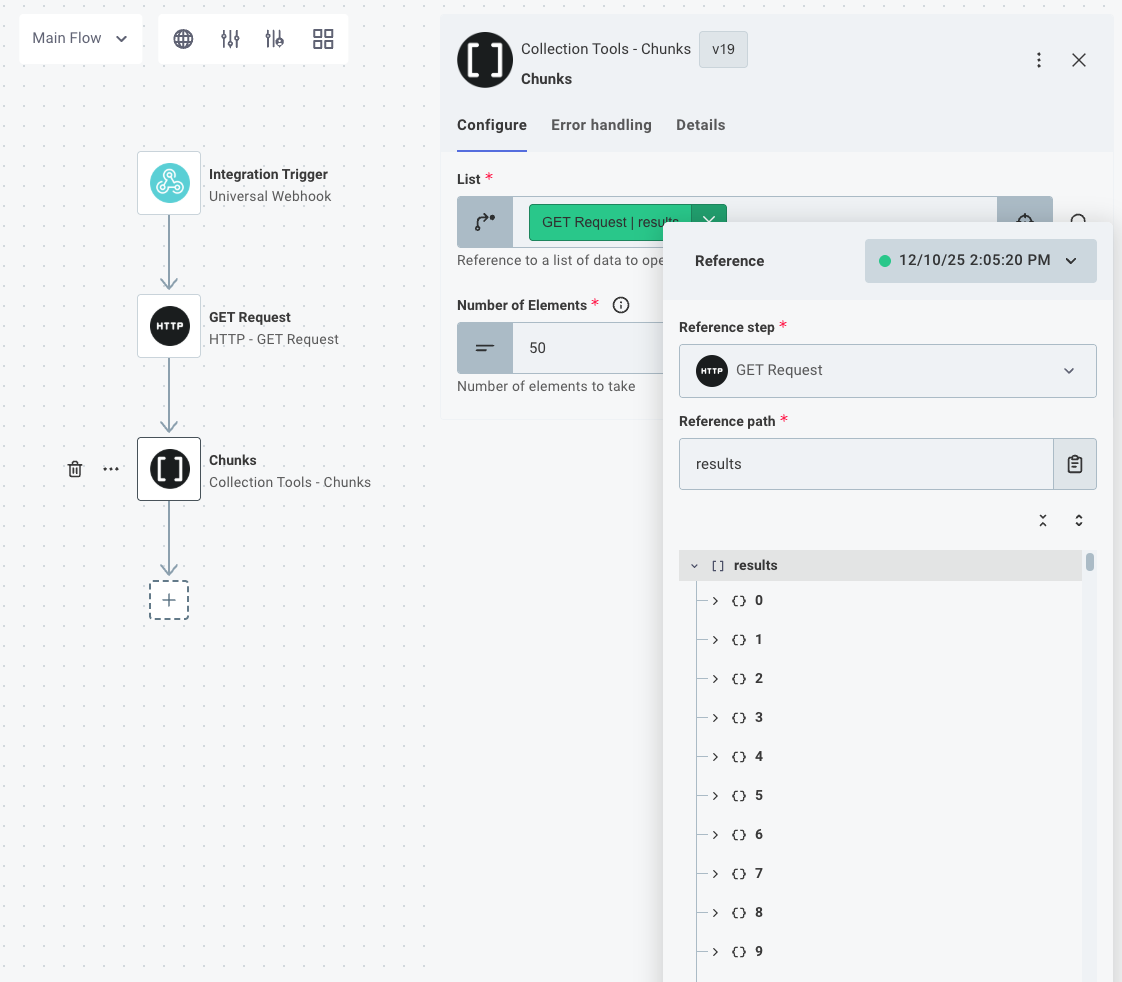
If your data is not evenly divisible by the number of elements you specify, the Chunks action puts the remaining elements in the last chunk. For example, if you have 108 records, and split them into chunks of 25, you'll get 4 chunks of 25 records, and 1 chunk of 8 records.
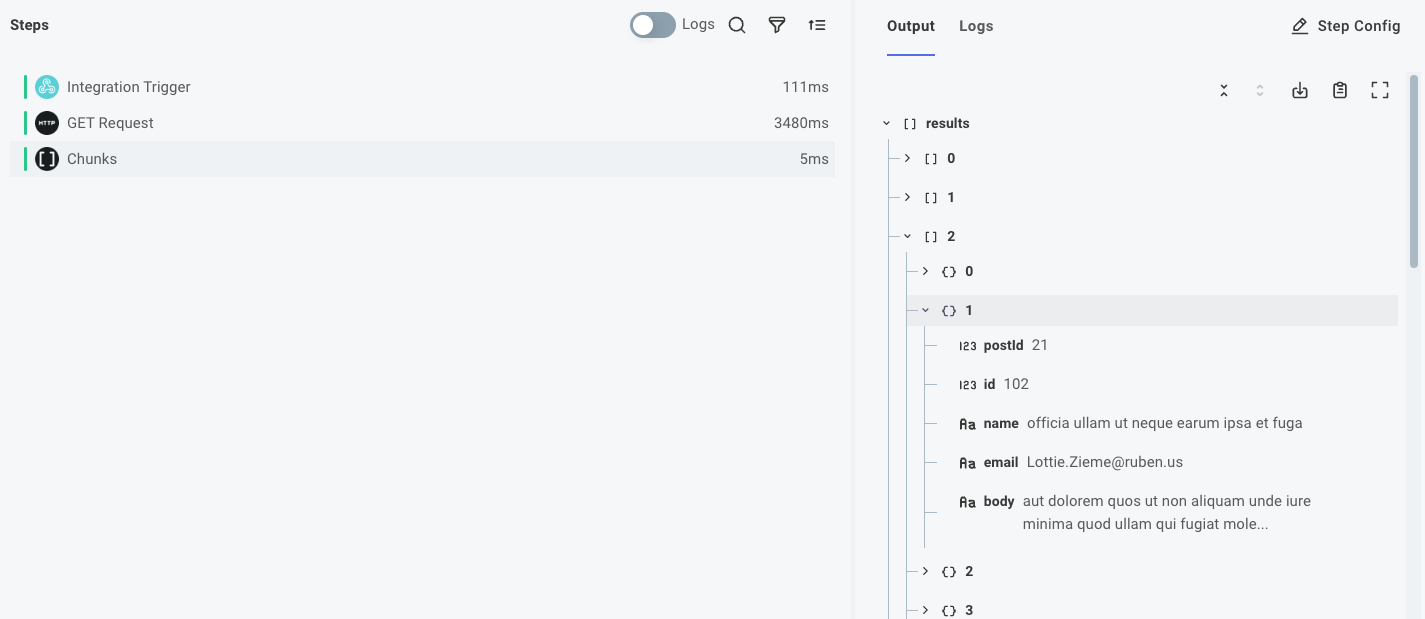
If you open the chunks action's results, you can see 10 groups of 50 records each.
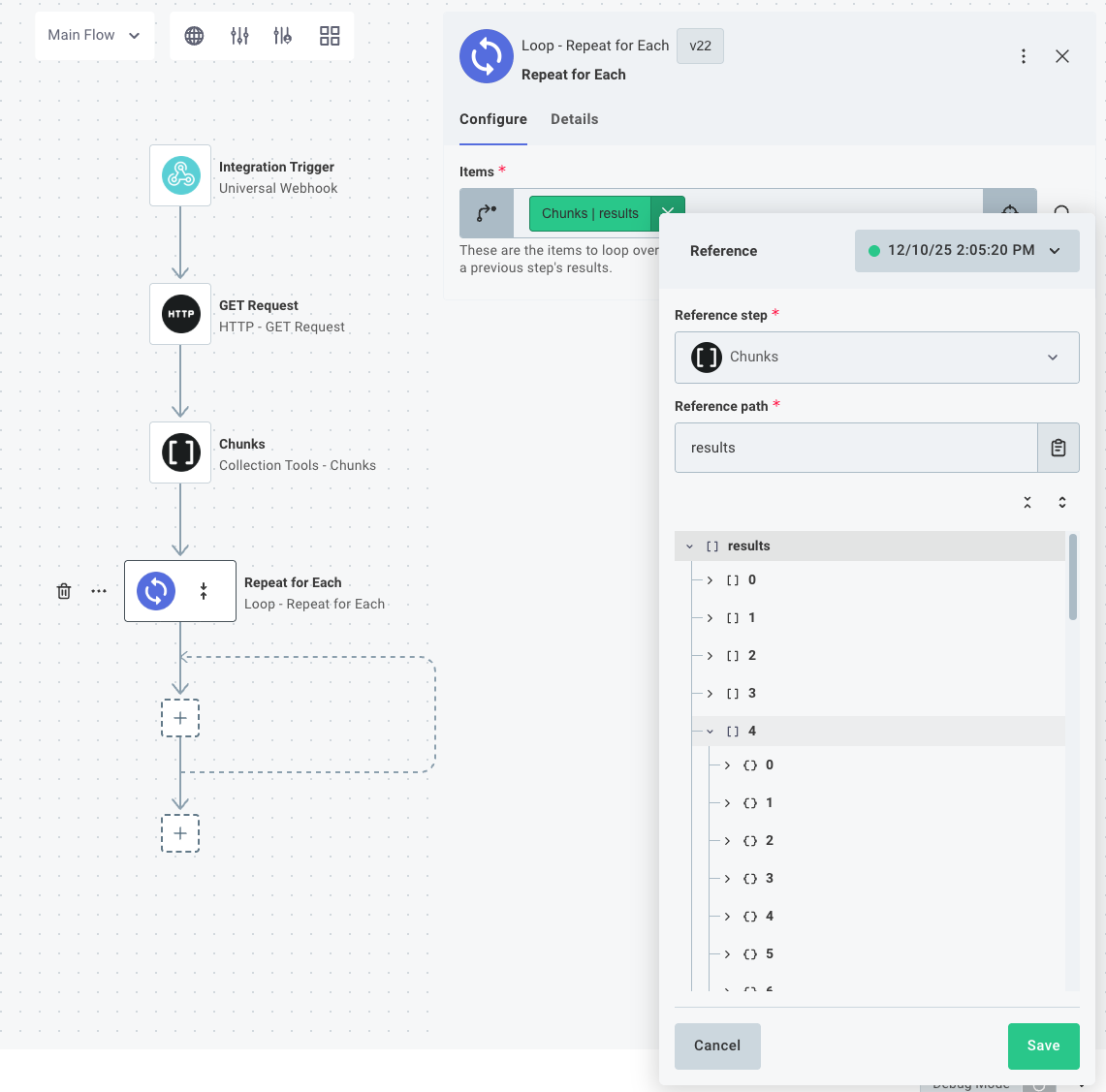
Loop over each chunk
Next, add a Repeat for Each action to your integration and configure it to loop over the chunks you generated.
Send each chunk to a sibling flow
You need to send each chunk of records to a sibling flow. To accomplish that, you'll use cross-flow invocations.
You'll add an Invoke Flow step to your integration, and select a sibling flow to send the chunk to.
So, first add a sibling flow that has a Cross-Flow Trigger.
Then, select the sibling flow for your Invoke Flow step's Flow Name input.
Reference the Repeat for Each's currentItem property for the Data input of the Invoke Flow action - that'll represent the current chunk of records and will configure the step to send the chunk of records to the sibling flow.
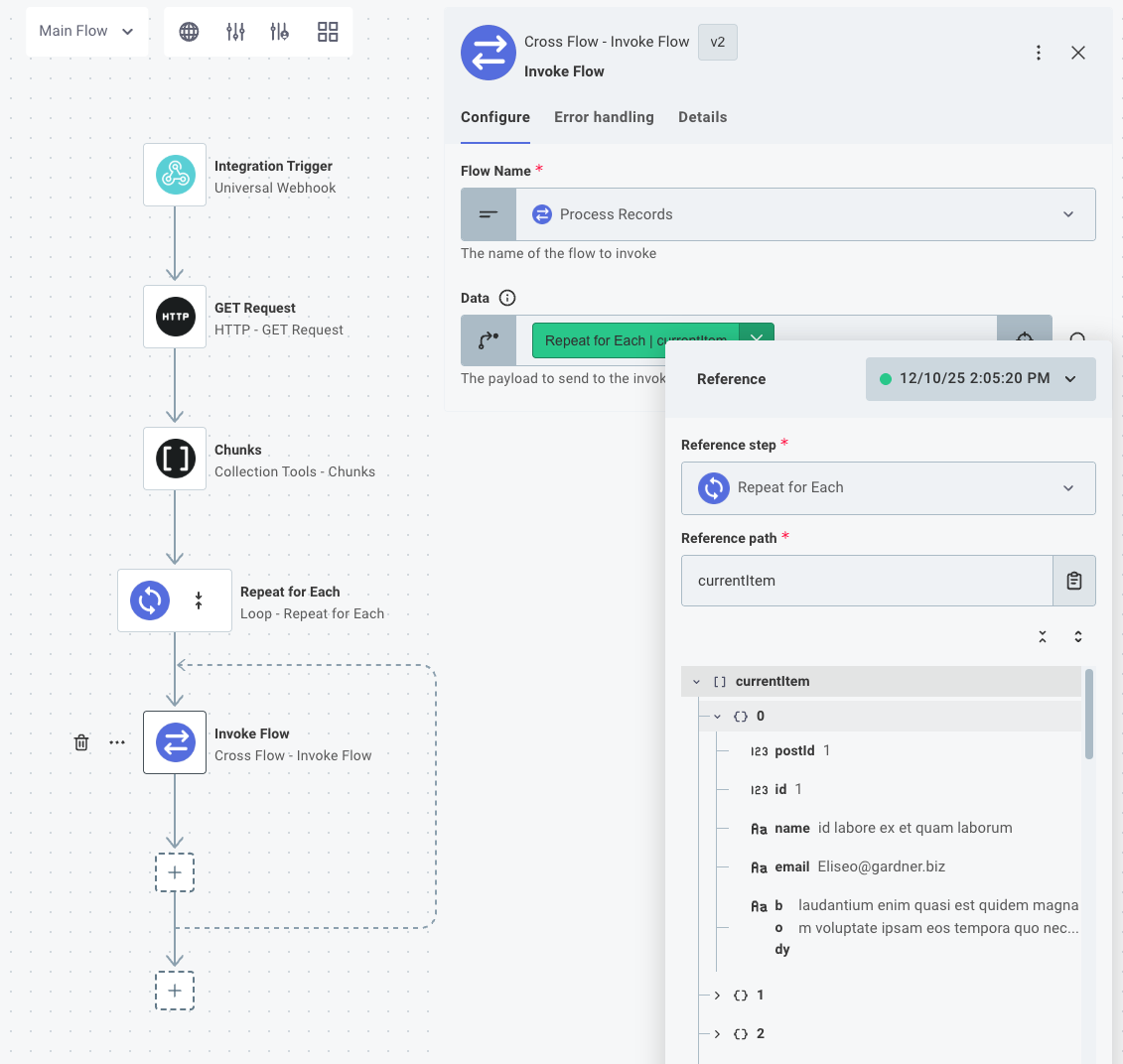
If you open the Process Records flow after running a test of the parent flow, you can see that Process Records was invoked ten times, and each invocation received a chunk of 50 records.
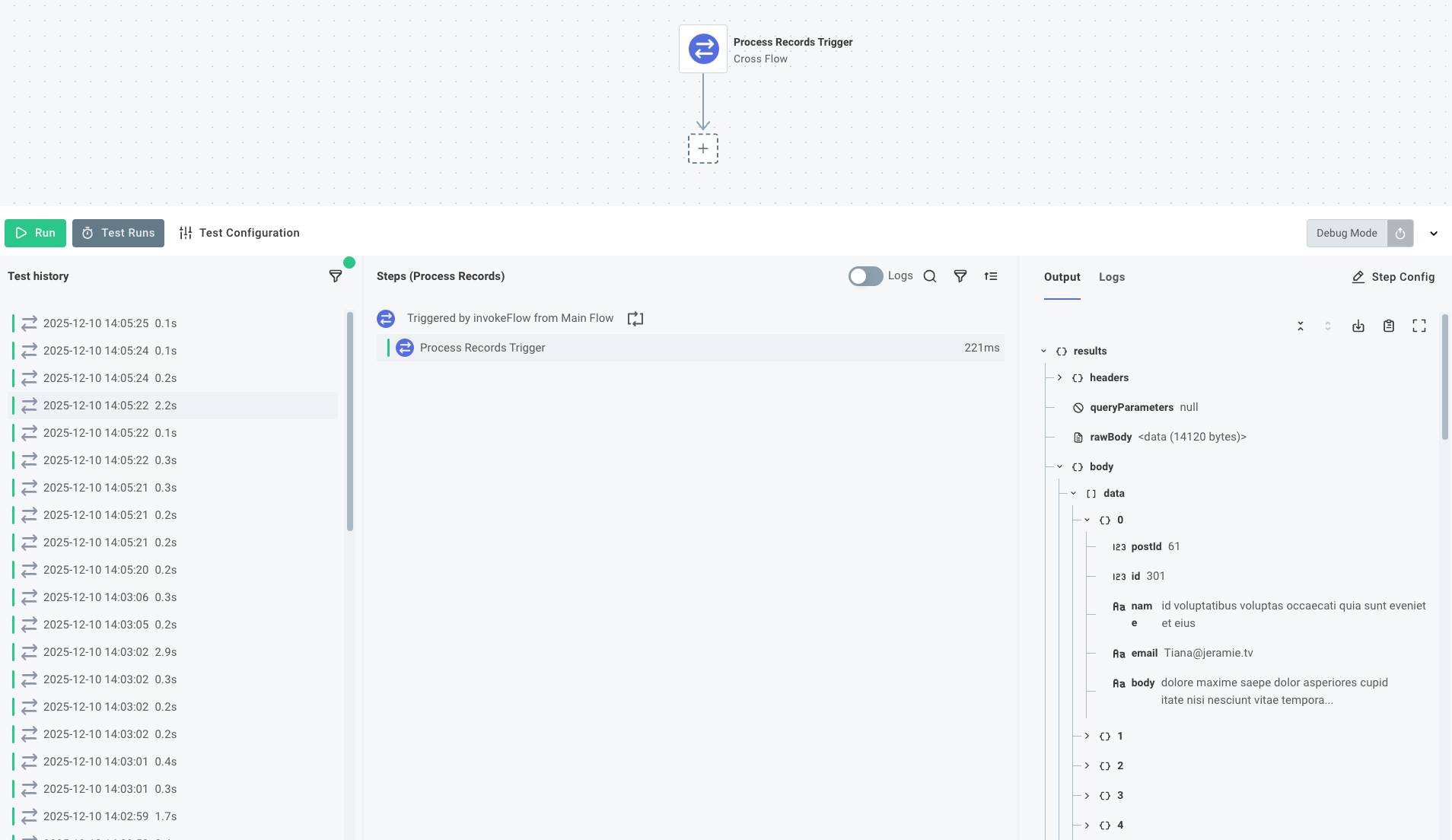
By default, Prismatic executions are asynchronous, meaning that our main flow will not wait for an invocation of the Process Records flow to complete before beginning the next invocation. This allows us to process multiple chunks of records simultaneously, effectively processing data in parallel.
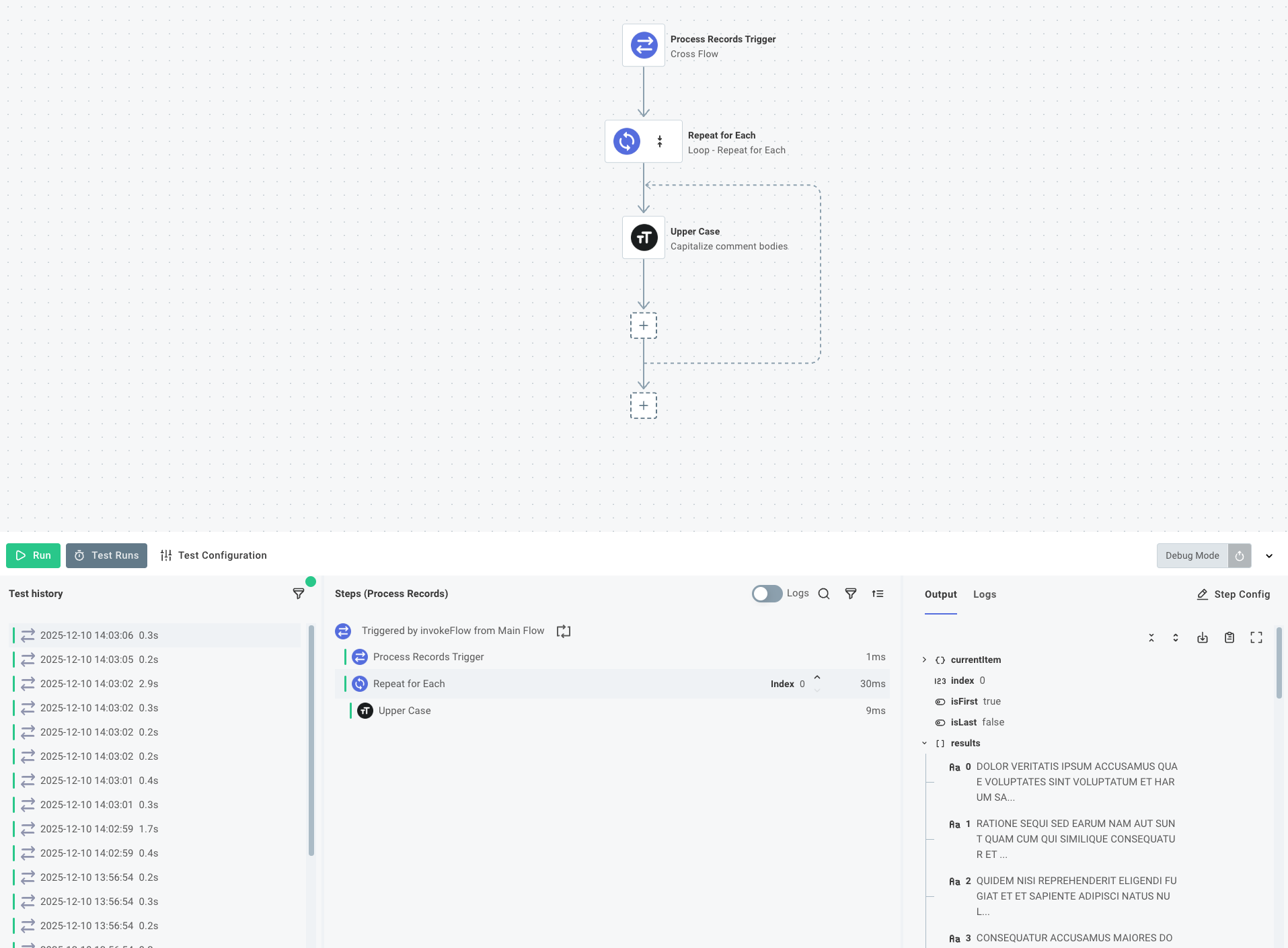
Process each chunk in the sibling flow
Now that the integration sends records to the sibling flow, you can process each chunk of records in parallel. You'll need to add business logic to your integration and connect it to APIs to fetch or update records. For this example, you'll capitalize the body of each comment:
(Optional) Aggregate the results
If you're pulling data from a source and sending it to a destination, you may not need to aggregate the results. But, if your integration is bidirectional or if you need to aggregate the results for any other reason, you can fetch the results of each parallel invocation using the execution IDs that the HTTP POST action returned.
If you look at the step results of the Repeat for Each action, you'll see that the action returns an array of execution IDs from the HTTP POST action.
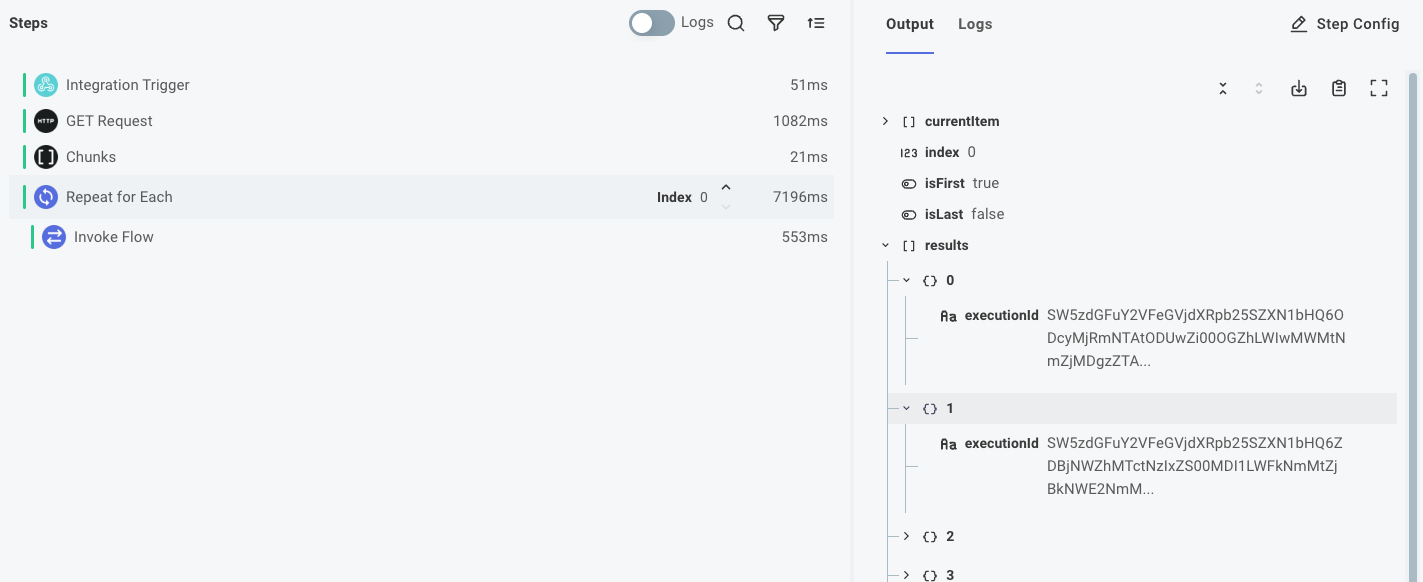
You can loop over these execution IDs and fetch the results of each invocation. To accomplish that, you'll:
- Loop over the execution IDs
- Loop up to 10 times using the Repeat X Times action
- Check if the execution is finished by querying the Prismatic API
- If it's finished, fetch the step results of a step in the sibling flow. Break the inner loop.
- If it's not finished, sleep for a few seconds and check again
Fetch step results from the Prismatic API
You can use the Prismatic component's Raw GraphQL Request action to query the step results of a step in the sibling flow.
query myGetExecutionResults($executionId: ID!, $stepName: String!) {
executionResult(id: $executionId) {
id
endedAt
stepResults(displayStepName: $stepName) {
nodes {
resultsUrl
}
}
}
}
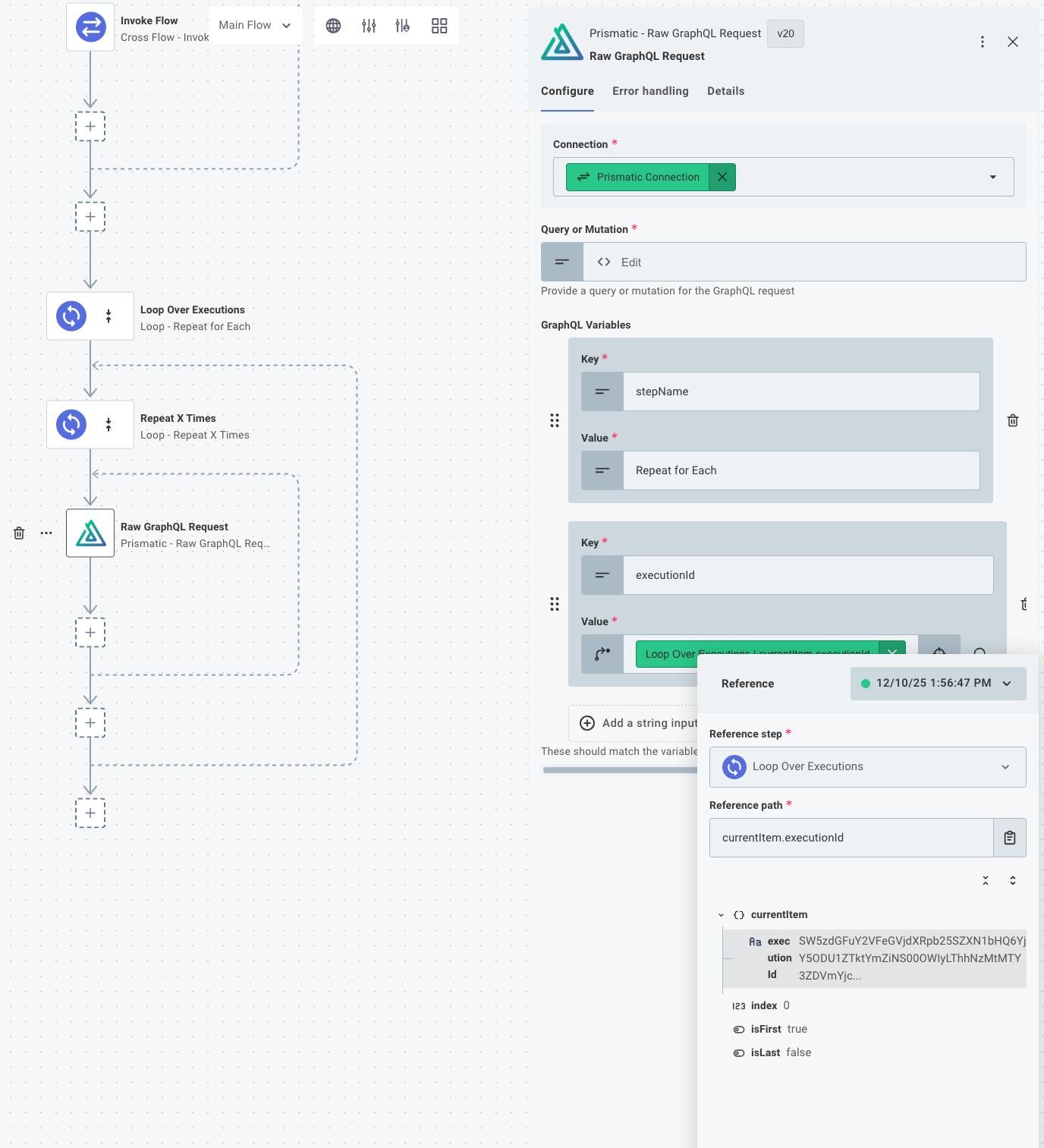
If the execution is finished (indicated by whether or not endedAt has a value), you can use the resultsUrl to fetch the step results of a step in the sibling flow, and then break the loop.
If the execution is not finished, the integration sleeps and then checks again.
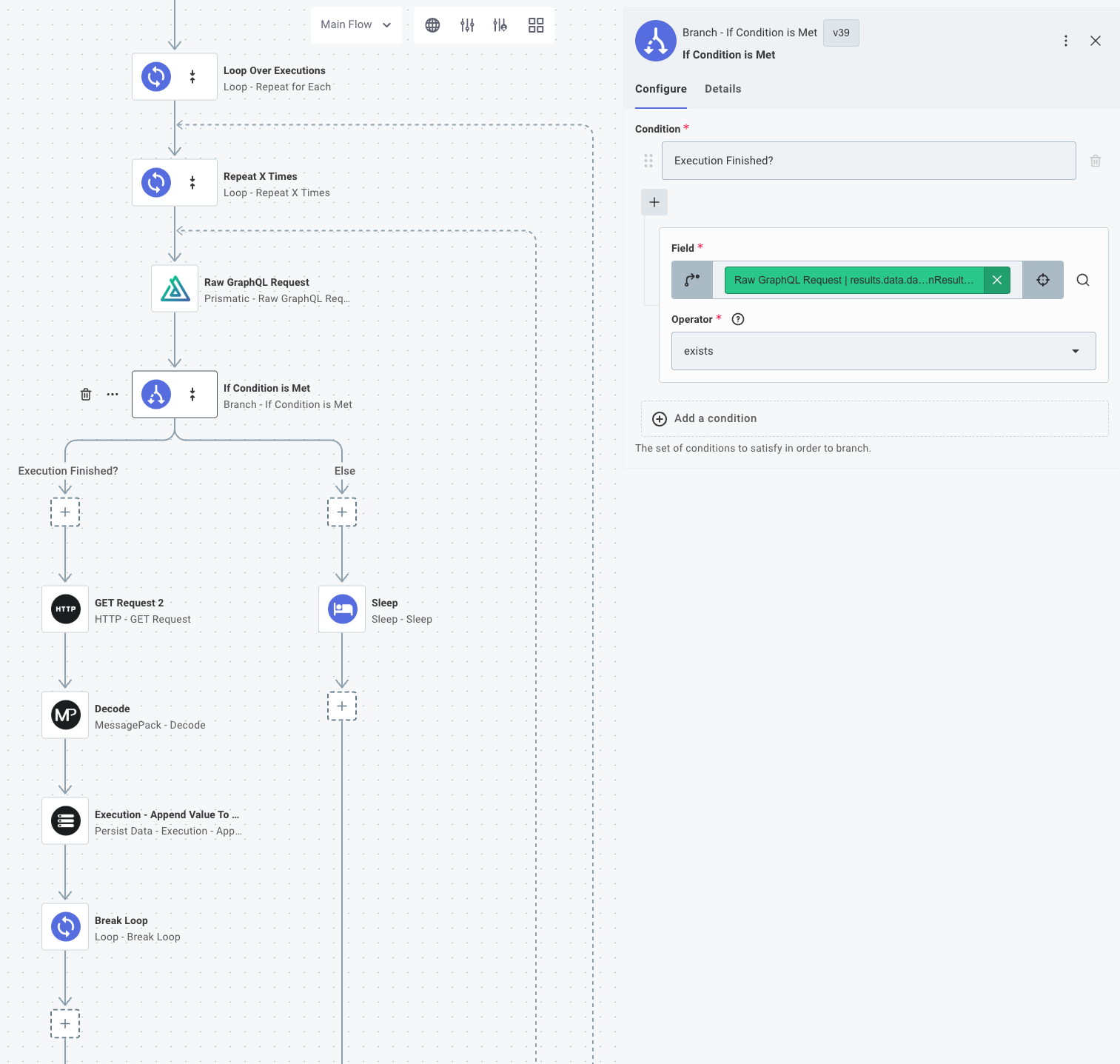
A few notes:
- Prismatic stores step results as binary files in S3 and compresses them using MessagePack. Since they are binary files, you need to set the GET Request action's Response Type to Binary.
- You need to decompress the step results using the MessagePack Decompress action.
- You can either process the step results in the loop, or save the results to an array using the Persist Data's Execution - Append Value to List action to aggregate the results into a single array. That's what the example integration does.
Process the results
Finally, you can load the array of step results using an Execution - Get Value action. The results will be an array of arrays, so you can use the Collection Tools component's Flatten action to flatten the array of arrays into a single array. When you do that in the example, you get an array of 500 records, each with a capitalized body.
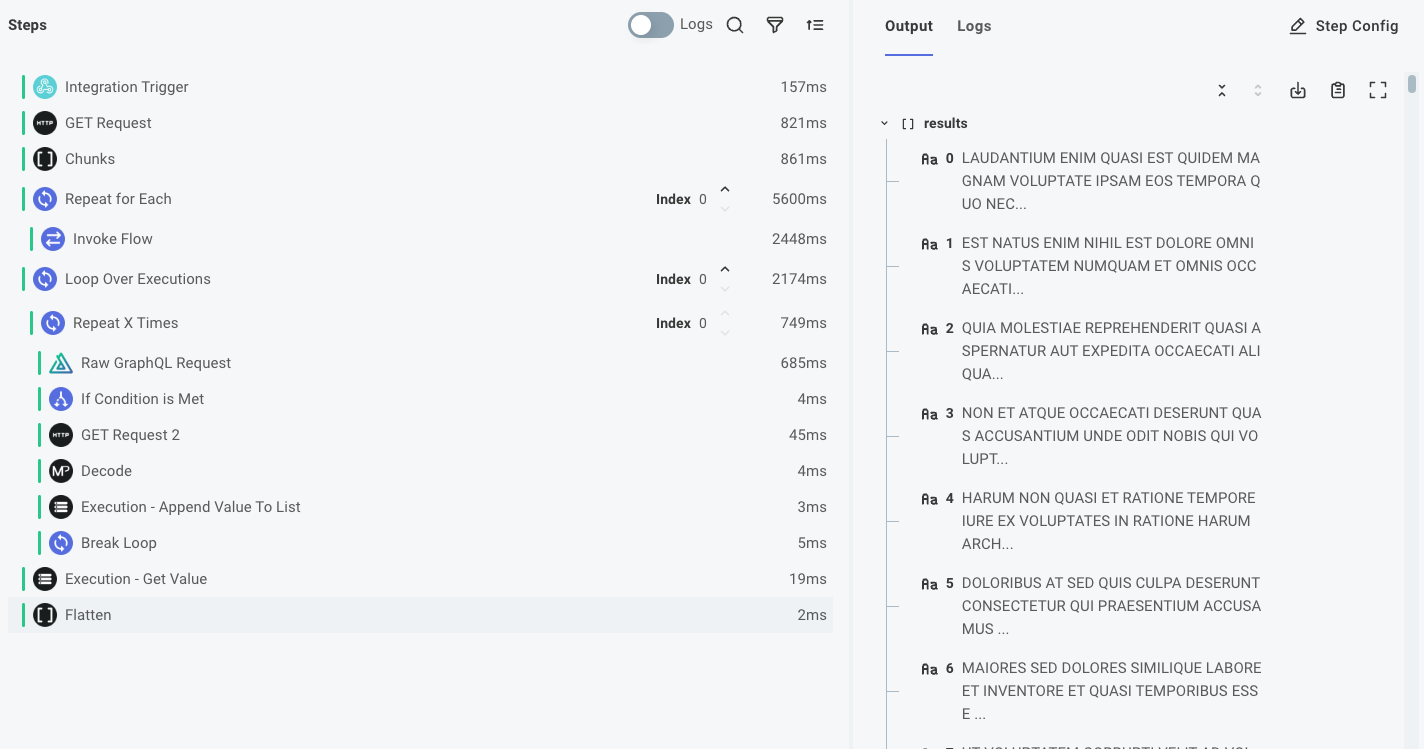
You can then process each record in the array of results.
Limitations and considerations
There are several limitations and considerations to keep in mind when processing data in parallel:
Simultaneous Execution Limit. The number of concurrent executions your organization can run is determined by your pricing plan. If you try to run more than that many executions at once, you may receive a 429 Too Many Requests error, and will need to handle that in your integration.
Execution Time Limit. An execution can run for up to 15 minutes. If your execution takes longer than 15 minutes, it will be terminated. When sizing chunks of records, consider how many can be processed within 15 minutes.
Payload size limit. A webhook request can be up to approximately 6MB in size. If a chunk of records exceeds 6MB, the chunks will need to be smaller.
Rate limits. The APIs you integrate with may have rate limits, and parallelizing requests may exceed those limits. Be sure to check the rate limits of the APIs you integrate with. If you run into rate limiting constraints, consider running your flows in sequence with a recursive trigger.
For information on Prismatic integration limits, see Integration Limits.