Automatic Execution Retry
Integration executions can fail due to temporary issues like network timeouts or brief third-party service outages. Automatic retry allows your integrations to attempt execution again after a failure, improving reliability without manual intervention.
Integration retry configuration
You can configure your asynchronously-invoked instances to retry if they fail to run to completion. This is especially useful if your integration relies on an unreliable third-party API that may experience brief outages. By enabling retry, your integration can attempt execution again after a short delay, reducing unnecessary alerting and manual intervention.
To enable automatic retry, select your trigger and then choose Flow retry.
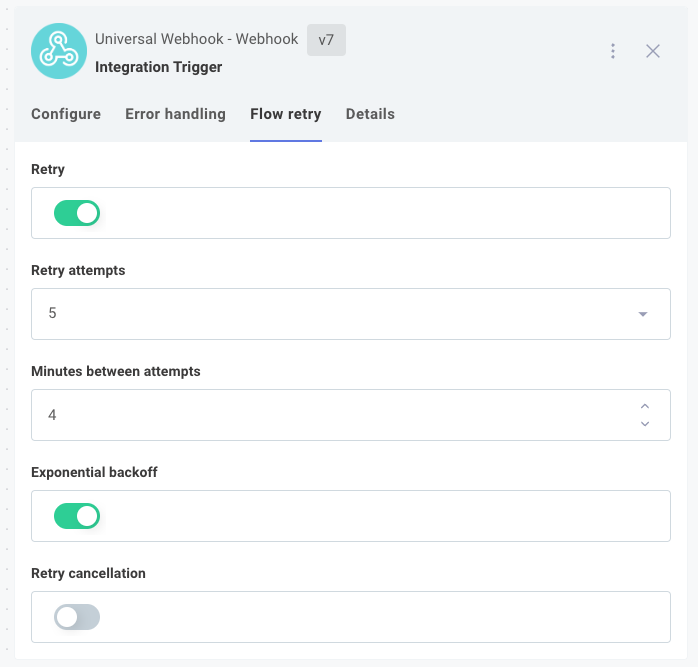
Retry Attempts specifies the maximum number of times (up to 10) Prismatic will attempt to run the same instance invocation after a failure. If the number of failures exceeds Retry Attempts, the execution is marked as failed and any configured alert monitors will fire.
Minutes Between Attempts sets the interval (in minutes) between retry attempts. For example, if set to 4 minutes and the first attempt fails at 10:24, subsequent attempts will occur at 10:28, 10:32, 10:36, 10:40, and 10:44 if failures persist.
Note: Retry intervals are precise to the minute (not the second). Thus, a retry scheduled for 4 minutes after a failure at 10:24 may occur at 10:28 or 10:29.
If Exponential Backoff is enabled, the interval between retries increases exponentially (factor of 2). For example, with Minutes Between Attempts set to 3 and Exponential Backoff enabled, retries will occur after 3, 6, 12, 24, and 48 minutes.
Note: The maximum delay before a retry is 24 hours. If exponential backoff would result in a longer delay, the retry will occur after 24 hours instead.
Retry Cancellation allows you to cancel pending retries if a more recent invocation occurs. For example, if your integration processes payloads with unique IDs, you may want to cancel retries for older invocations when new data arrives, preventing outdated data from overwriting newer updates.
To configure retry cancellation, select a unique request ID from the trigger payload.
For example, you might pass in a header, x-my-unique-id: abc123 as part of your trigger payload.
If another invocation with that header comes in that updates resource abc123, you might want to cancel currently queued retries.
To do that, select your trigger's results.headers.results.headers.x-my-unique-id reference as your Unique Cancellation ID.
Cancellation IDs do not need to be headers. Instead, you can select a key from the payload body. For example, if your instance invocation looks like this:
curl 'https://hooks.prismatic.io/trigger/EXAMPLE==' \
--location \
--header "Content-Type: application/json" \
--data '{"productId":"abc123","price":"250","description":"A box of widgets"}'
You can key your unique cancellation ID off of results.body.data.productId.
For more information, see Instance retry and replay.