Processing Data with Recursive Flows
Suppose your customers have a large number of records in a CRM that you need to sync to your app when an integration is deployed. Processing large amounts of data can take considerable time. For example, if your customers have around 100,000 records, and you know from testing that you can fetch and process about 10 records per second, then doing some back-of-the-envelope math you'll find it'll take almost 3 hours to do an initial sync of those records.
But, an execution can run for a maximum of 15 minutes. To process 3 hours of data, you'll need to split the work across at least 12 executions.
You can accomplish this in one of two ways:
- You can parallelize the work, running 12 executions concurrently. Processing Data in Parallel documents how to do that. Note that with this strategy you may run into execution concurrency or third-party API rate limits if you run too many executions in parallel.
- Run several executions in series, allowing one execution to process a chunk of data and then call itself with a cursor noting where it left off. This document details how to run a flow recursively to process large amounts of data.
Recursive flows
A recursive flow is a flow that calls itself. In Prismatic, they're useful when processing large datasets that take longer than 15 minutes to process.
One execution processes a number of records you know can be processed within the time constraints, and then it calls itself with a cursor indicating where it left off. The next execution continues the work.
Typically, a recursive flow looks something like this:
If the API you're integrating with is paginated (i.e. you fetch page 1 of records, then page 2, etc.), your first execution might loop 20 times, fetch pages 1-20, and then it'll call itself with a cursor of 21, indicating that the next execution should process pages 21-40.
The recursive flow component
The recursive flow component can be used to build recursive flows. It contains a trigger and three actions:
- The Recursive Trigger takes a JSON payload in the shape of
{"cursor": "some-cursor"}. If a cursor is passed to it, it saves that cursor to execution state for use by the flow. If a cursor is not present, it defaults to some default value that you provide as an input. - The Invoke Recursive Trigger action reads the current cursor from execution state and calls its own trigger to start a new execution.
- The Get Recursive Cursor action reads the current cursor from execution state and returns it. This is handy to use at the top of a loop to fetch the current cursor value.
- The Set Recursive Cursor action saves a given value to the cursor in execution state, which is then read by a Get Recursive Cursor or Invoke Recursive Trigger action.
Running an initial data import
If you would like your recursive flow to run when a customer deploys an instance of your integration, toggle the trigger's Run on Deploy? to true.
Supply a reasonable Default Cursor Value which will be used in the first execution of the flow.
For example, you could enter 1970-01-01 00:00:00 if your cursor is an "Updated At" timestamp, or 0 if your cursor is a paginated API page value.
Note that a deploy flow runs each time an instance is deployed. So, if a customer deploys an instance, and then reconfigures the instance and re-deploys it, the recursive trigger will begin twice.
Ensure that your flows are built in an idempotent way. You could, for example, set a flow state persisted value when initial import completes, and short-circuit your flow if an initial import has previously completed.
Calling the recursive trigger yourself
If you would like to call a recursive trigger yourself to begin a series of executions, you can invoke your flow's webhook URL (as you would a standard webhook trigger).
If you would like to override the default cursor value, and supply your own cursor value, POST a request in the format {"cursor": "some-cursor"}.
For example,
curl 'https://hooks.prismatic.io/trigger/SW5zexample==' \
--location \
--header "Content-Type: application/json" \
--data '{"cursor":"2000-01-01 00:00:00"}'
This is helpful if the initial recursive cursor you want to use is a dynamic value - you can have one flow compute the value (e.g. "Datetime 3 years ago"), and call your recursive flow with that value.
Stopping a recursive flow
When a flow calls itself, it's easy to accidentally create an infinite loop. Ensure that you have logic within your flow that leads away from an Invoke Recursive Trigger action when data processing completes.
If you do run into an infinite loop:
- If you're in the integration designer, add a Stop Execution step to the top of your flow and hit 'save' to cause the next execution to stop before it calls itself again.
- If you have an instance deployed to a customer that is in an infinite loop, disable the instance for a short time. The next time the instance's flow attempts to call itself, it won't be able to.
Example recursive flows
This integration in our GitHub examples repository contains four flows that illustrate how to loop over various paginated APIs:
You can import the integration into your own tenant for testing.
JSON Placeholder example recursive flow
The JSON Placeholder Example flow loops over JSON Placeholder's comments API, retrieving 5 pages of 15 records each execution. JSON Placeholder uses page numbers as pagination tokens (i.e. page 1, page 2, etc.), so this flow processes pages 1 through 5 during its first execution, then 6-10, 11-15, etc.
No authentication is required for this flow.
PostgreSQL example recursive flow
The PostgreSQL Example flow loops over records in a PostgreSQL table.
It uses a createdat column on the table as a cursor.
It starts by querying all records created after UNIX epoch (1970-01-01), takes note of the last record's createdat value as a cursor, and then the next loop or execution fetches records with a createdat value larger than the cursor it stored.
To test this flow locally, you'll need to spin up a PostgreSQL database that is publicly accessible (or accessible with an on-prem agent).
Then, you'll need to create a table with records that have a createdat timestamp.
Salesforce example recursive flow
The Salesforce Example flow loops over Contact records in SFDC.
It uses the SOQL query language to order and fetch records.
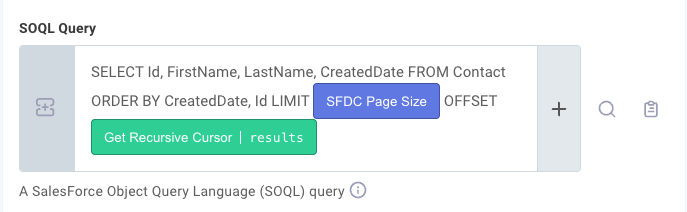
This flow uses SOQL's OFFSET property to fetch pages.
First it fetches records 1-5, then it fetches 5 more records with OFFSET 5, so it gets records 6-10, etc.
To test this flow, you'll need a Salesforce account with basic auth, or you will need to update the connection to use OAuth 2.0.
Prismatic example recursive flow
The Prismatic API Example flow dog-foods Prismatic's API and loops over components (connectors) in Prismatic, fetching 5 pages of 10 connectors each execution. Prismatic's API returns a cursor that can be used in a subsequent query to fetch additional records.
To test this flow, run prism me:token --type refresh to generate a refresh token for the Prismatic connection to use.
Tracking recursive invocation lineage
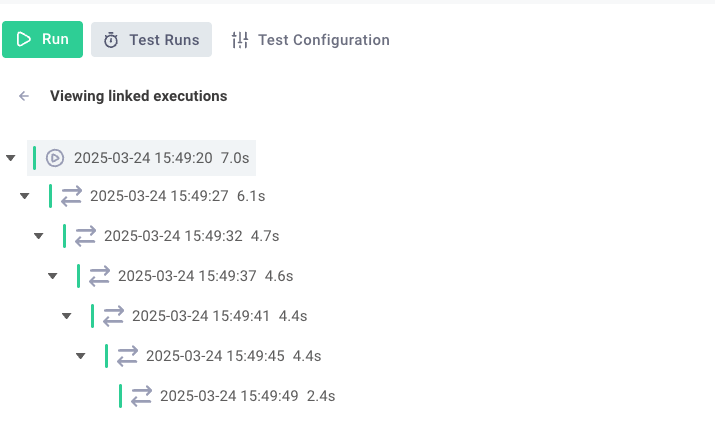
When a flow invokes another flow, either with the recursive flow or cross-flow components, that call lineage is tracked. This way, you can see that execution A called execution B, which called execution C, etc.
To view lineage in the low-code designer, select View linked executions from the first execution that ran. There, you will see which execution invoked which subsequent execution, as well as what cursor was sent to each trigger.
Recursive flows in code-native
If you're building a recursive flow in a code-native integration, you can accomplish the same pattern using context.invokeFlow with the current flow's name and a cursor value.
Your flow's onExecution function can reference the cursor from the trigger's results.body.data.cursor property (if it exists), or default to some value.
Here, we use numeric pagination, defaulting to 0 and incrementing the cursor by 1 each time. You can adapt this pattern to whatever cursor type you're using.
export const exampleRecursiveFlow = flow({
name: "Example Recursive Flow",
stableKey: "example-recursive-flow",
description: "Example of a recursive flow",
onExecution: async (context, stepResults) => {
// Get cursor from trigger payload (or default to 0)
let cursor =
(stepResults.onTrigger.results.body.data as Record<string, number>)
.cursor || 0;
context.logger.info(`Cursor value is ${cursor}`);
/* Do work here */
// Increment cursor and invoke the current flow with the updated cursor
await context.invokeFlow(context.flow.name, { cursor: ++cursor });
return { data: null };
},
});